分布式词向量
word2vec
一、简介

word2vec本质上是只具有一个隐含层的神经元网络。它的输入是采用One-Hot编码的词汇表向量,它的输出也是One-Hot编码的词汇表向量。使用语料来训练这个神经网络直到收敛,然后从输入层与隐藏层之间的权重就是每一个词的词向量。word2vec分为CBOW和Skip-Gram两种模型。CBOW模型的训练输入时某一个特征的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram模型和CBOW的思路时反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文的词向量。CBOW对小型数据库比较合适,而Skip-Gram再大型语料库中表现更好。
二、神经概率语言模型
神经概率语言模型通常包括三个层:输入层、投影层和输出层。其中W和U是权重矩阵,p和q是偏置向量。

对于语料C中的任意一个词w,将Context(w)取为其前面的n-1个词,这样对与(Context(w),w)就是一个训练样本了。
这是神经网络的计算公式。假设有n-1个样本,要生成长度为m词向量,那么投影层的规模就是(n-1)m,输出层的规模就是N。然后还需要使用softmax对输出的向量归一化来表示概率。
三、CBOW
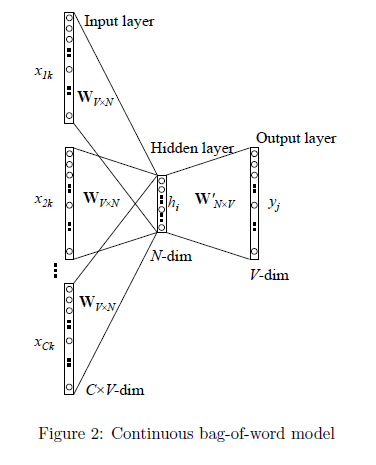
1、输入层:上下文单词的One-Hot编码词向量,V为词汇表单词个数,C为上下文单词个数。以上文那句话为例,这里C=4,所以模型的输入是(is,an,on,the)4个单词的One-Hot编码词向量。
2、初始化一个权重矩阵 ![[公式]](/img/loading.gif)
3、将所得的向量
4、初始化另一个权重矩阵
5、y中概率最大的元素所指示的单词为预测出的中间词(target word)与true label的One-Hot编码词向量做比较,误差越小越好(根据误差更新两个权重矩阵)
在训练前需要定义好损失函数(一般为交叉熵代价函数),采用梯度下降算法更新W和W’。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的Distributed Representation表示的词向量,也叫做word embedding。因为One-Hot编码词向量中只有一个元素为1,其他都为0,所以第i个词向量乘以矩阵W得到的就是矩阵的第i行,所以这个矩阵也叫做look up table,有了look up table就可以免去训练过程,直接查表得到单词的词向量了。
四、Skip-gram
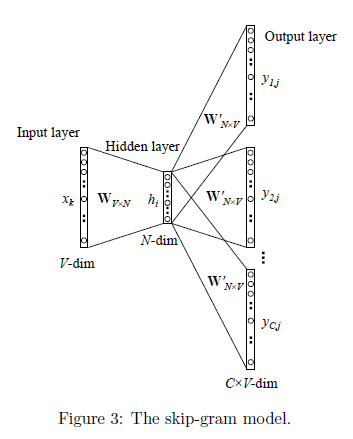
Skip-Gram是给定input word来预测上下文,其模型结构如上图所示。它的做法是,将一个词所在的上下文中的词作为输出,而那个词本身作为输入,也就是说,给出一个词,希望预测可能出现的上下文的词。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型。“apple”的上下文词是(’there’,’is’,’an’,’on’,’the’,’table’).那么以apple的One-Hot词向量作为输入,输出则是(’there’,’is’,’an’,’on’,’the’,’table’)的One-Hot词向量。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量(和CBOW中一样)。接下来具体介绍如何训练我们的神经网络。
假如我们有一个句子“There is an apple on the table”。
1、首先我们选句子中间的一个词作为我们的输入词,例如我们选取“apple”作为input word;
2、有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是[‘is’,’an’,’apple’,’on’,’the’ ]。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 (‘apple’, ‘an’),(‘apple’, ‘one’)。
3、神经网络基于这些训练数据中每对单词出现的次数习得统计结果,并输出一个概率分布,这个概率分布代表着到我们词典中每个词有多大可能性跟input word同时出现。举个例子,如果我们向神经网络模型中输入一个单词“中国“,那么最终模型的输出概率中,像“英国”, ”俄罗斯“这种相关词的概率将远高于像”苹果“,”蝈蝈“非相关词的概率。因为”英国“,”俄罗斯“在文本中更大可能在”中国“的窗口中出现。我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。
4、通过梯度下降和反向传播更新矩阵W
5、W中的行向量即为每个单词的Word embedding表示
这个公式对应着两个连乘,第一个连乘是对应 T 个输入样本,也就是说我们文本中的每个单词都要做中心词。第二个连乘代表着给定一个中心词的情况下,窗口中的单词出现的概率,内含相互独立的假设。
五、Hierarchical Softmax
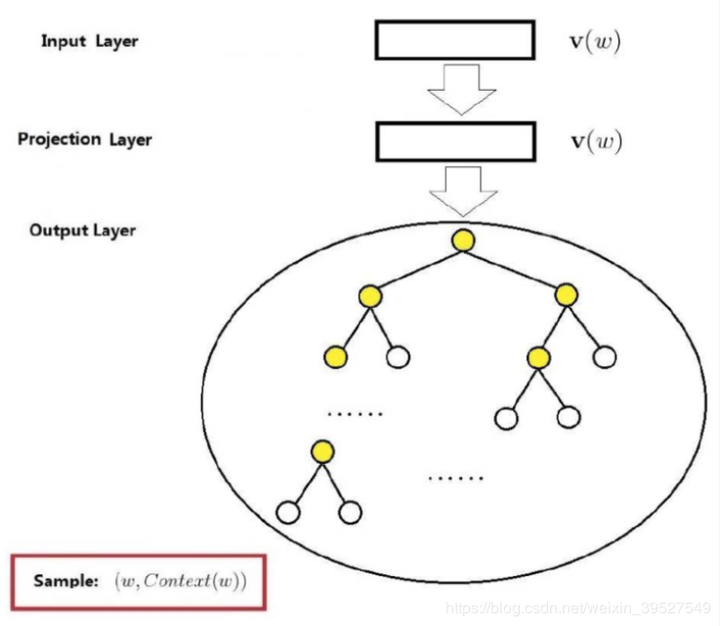
Hierarchical Softmax对原模型的改进主要有两点,第一点是从输入层到隐藏层的映射,没有采用原先的与矩阵W相乘然后相加求平均的方法,而是直接对所有输入的词向量求和。假设输入的词向量为(0,1,0,0)和(0,0,0,1),那么隐藏层的向量为(0,1,0,1)。
Hierarchical Softmax的第二点改进是采用哈夫曼树来替换了原先的从隐藏层到输出层的矩阵W’。哈夫曼树的叶节点个数为词汇表的单词个数V,一个叶节点代表一个单词,而从根节点到该叶节点的路径确定了这个单词最终输出的词向量。
六、Negative Sampling
尽管哈夫曼树的引入为模型的训练缩短了许多开销,但对于一些不常见、较生僻的词汇,哈夫曼树在计算它们的词向量时仍然需要做大量的运算。
负采样是另一种用来提高Word2Vec效率的方法,它是基于这样的观察:训练一个神经网络意味着使用一个训练样本就要稍微调整一下神经网络中所有的权重,这样才能够确保预测训练样本更加精确,如果能设计一种方法每次只更新一部分权重,那么计算复杂度将大大降低。
将以上观察引入Word2Vec就是:当通过(”fox”, “quick”)词对来训练神经网络时,我们回想起这个神经网络的“标签”或者是“正确的输出”是一个one-hot向量。也就是说,对于神经网络中对应于”quick”这个单词的神经元对应为1,而其他上千个的输出神经元则对应为0。使用负采样,我们通过随机选择一个较少数目(比如说5个)的“负”样本来更新对应的权重。(在这个条件下,“负”单词就是我们希望神经网络输出为0的神经元对应的单词)。并且我们仍然为我们的“正”单词更新对应的权重(也就是当前样本下”quick”对应的神经元仍然输出为1)。
fasttext
fasttext与CBOW的模型架构很相似。在word2vec中把每个单词当作最小的单位,把每个单词都变成一个向量。这就忽略了单词的形态特征,比如”apple”和”apples”。这两个单词具有较多的公共字符,但在传统的word2vec中,这种单词的内部形态信息丢失了。为了克服这一问题,fasttext使用了字符级别的n-grams来表示一个单词。对于单词”apple”,假设n取值为3,则它的trigram有”
这带来两点好处:
对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
模型架构

fastText模型只有三层:输入层、隐含层、输出层,输入也是向量表示的单词,输出也是一个特定的target,隐含层是对多个词向量的叠加平均。不过CBOW的输入是目标单词的上下文,并且通过one-hot编码过。但fasttext的输入是对个单词及其n-gram特征,并且被embedding。值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。这两个知识点在前文中已经讲过,这里不再赘述。
fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
GloVe
glove模型也是一种转化为词向量的工具。首先基于语料库构建共现矩阵然后基于共现矩阵和glove模型学习词向量。
统计共现矩阵
设共现矩阵为X,其元素为Xi,j
Xi,j的意义为:在整个语料库中,单词i和单词j共同出现在一个窗口中的次数。
比如一段话i love you but you love him i am sad,涉及到七个单词i、love、you、but、him、am、sad。
如果采用窗口宽度为5,左右为2的统计窗口,那么就有9个窗口。以中心词为love,语境词为but、you、him、i的窗口为例子。则
使用窗口将整个语料库遍历一遍,即可得到共现矩阵X。





参考
[1] https://blog.csdn.net/itplus/article/details/37999613
[2] https://zhuanlan.zhihu.com/p/61635013
[3]https://blog.csdn.net/u014665013/article/details/79642083
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!