Text-CNN
Text-CNN
一维卷积
一维卷积通常有三种类型:full卷积、same卷积和valid卷积,下面以一个长度为5的一维张量I和长度为3的一维张量K(卷积核)为例,介绍这三种卷积的计算过程
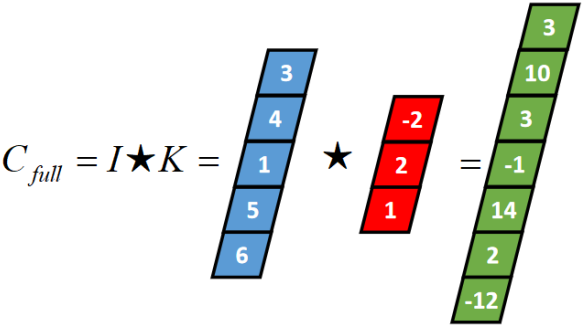
一维Full卷积
Full卷积的计算过程是:K沿着I顺序移动,每移动到一个固定位置,对应位置的值相乘再求和,计算过程如下:
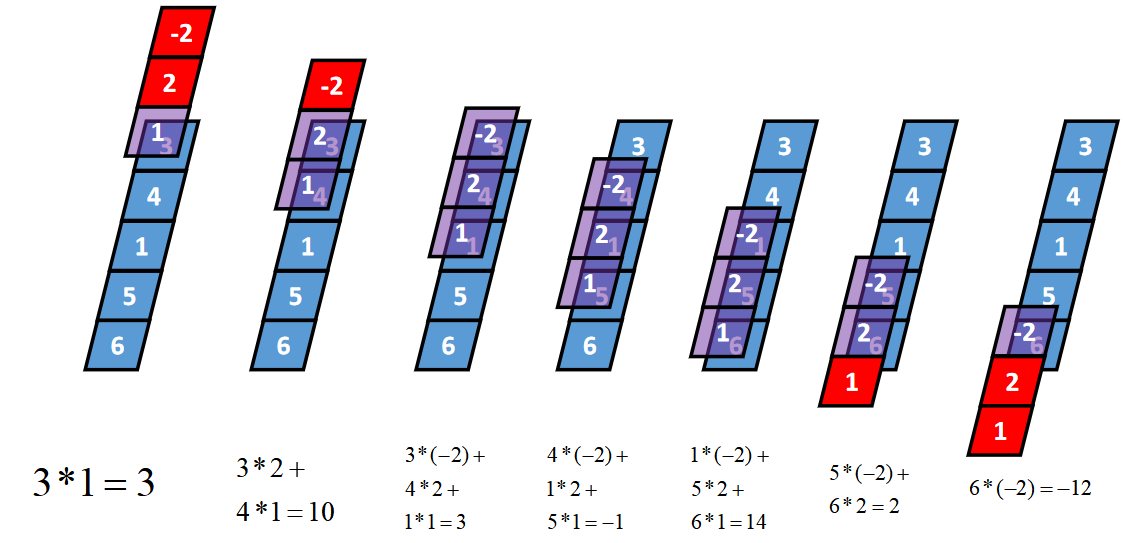
将得到的值依次存入一维张量Cfull,该张量就是I和卷积核K的full卷积结果,其中K卷积核或者滤波器或者卷积掩码,卷积符号用符号★表示,记Cfull=I★K
一维Same卷积
卷积核K都有一个锚点,然后将锚点顺序移动到张量I的每一个位置处,对应位置相乘再求和,计算过程如下:
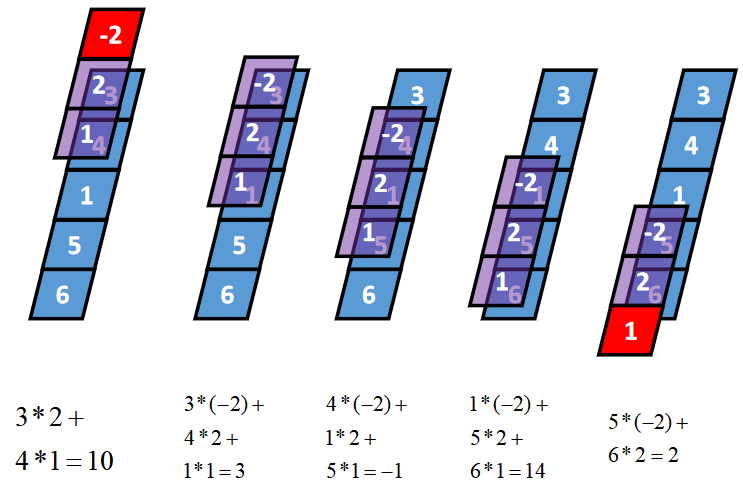
假设卷积核的长度为FL,如果FL为奇数,锚点位置在(FL-1)/2处;如果FL为偶数,锚点位置在(FL-2)/2处。
一维Valid卷积
从full卷积的计算过程可知,如果K靠近I,就会有部分延伸到I之外,valid卷积只考虑I能完全覆盖K的情况,即K在I的内部移动的情况,计算过程如下:

简介
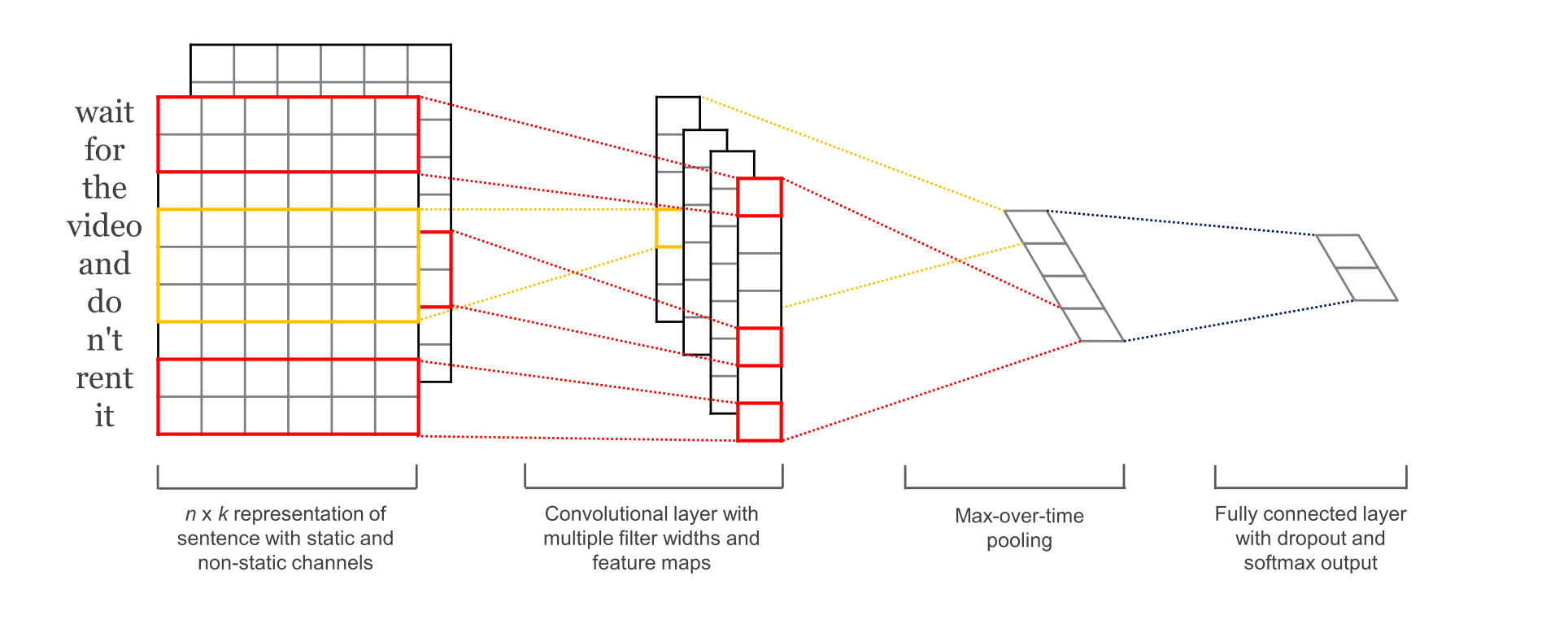
TextCNN是利用卷积神经网络来处理文本分类的一种模型。其思想与计算机视觉中的CNN大同小异。
参数与超参数
- sequence_length
Q: 对于CNN, 输入与输出都是固定的,可每个句子长短不一, 怎么处理?
A: 需要做定长处理, 比如定为n, 超过的截断, 不足的补0. 注意补充的0对后面的结果没有影响,因为后面的max-pooling只会输出最大值,补零的项会被过滤掉. - num_classes
多分类, 分为几类. - vocabulary_size
语料库的词典大小, 记为|D|. - embedding_size
将词向量的维度, 由原始的 |D| 降维到 embedding_size. - filter_size_arr
多个不同size的filter.
Embedding Layer
嵌入层是通过一个隐藏层, 将 one-hot 编码的词 投影 到一个低维空间中。
本质上是特征提取器,在指定维度中编码语义特征. 这样, 语义相近的词, 它们的欧氏距离或余弦距离也比较近。
Convolution Layer
为不同尺寸的 filter 都建立一个卷积层. 所以会有多个 feature map.
图像是像素点组成的二维数据, 有时还会有RGB三个通道, 所以它们的卷积核至少是二维的.
从某种程度上讲, word is to text as pixel is to image, 所以这个卷积核的 size 与 stride 会有些不一样.
- xixi
xi∈Rkxi∈Rk, 一个长度为n的句子中, 第 i 个词语的词向量, 维度为k. - xi:jxi:j
xi:j=xi⊕xi+1⊕…⊕xjxi:j=xi⊕xi+1⊕…⊕xj
表示在长度为n的句子中, 第 [i,j] 个词语的词向量的拼接. - hh
卷积核所围窗口中单词的个数, 卷积核的尺寸其实就是 hkhk. - ww
w∈Rhkw∈Rhk, 卷积核的权重矩阵. - cici
ci=f(w⋅xi:i+h−1+b)ci=f(w⋅xi:i+h−1+b), 卷积核在单词i位置上的输出. b∈RKb∈RK, 是 bias. ff 是双曲正切之类的激活函数. - c=[c1,c2,…,cn−h+1]c=[c1,c2,…,cn−h+1]
filter在句中单词上进行所有可能的滑动, 得到的 feature mapfeature map.
Max-Pooling Layer
max-pooling只会输出最大值, 对输入中的补0 做过滤.
Fulled-Connected Layer
使用dropout和softmax函数输出每个类别的概率。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!