语义相似度匹配模型-ESIM模型
语义相似度匹配模型-ESIM模型
ESIM是一个综合运用了BiLSTM和注意力机制的模型,在文本匹配中效果很好。
文本匹配简单来说就是分析两个句子之间的关系,比如有一个问题,现在给出一个答案,我们就需要分析这个答案是否匹配这个问题,所以本质上就是一个分类问题。
模型结构
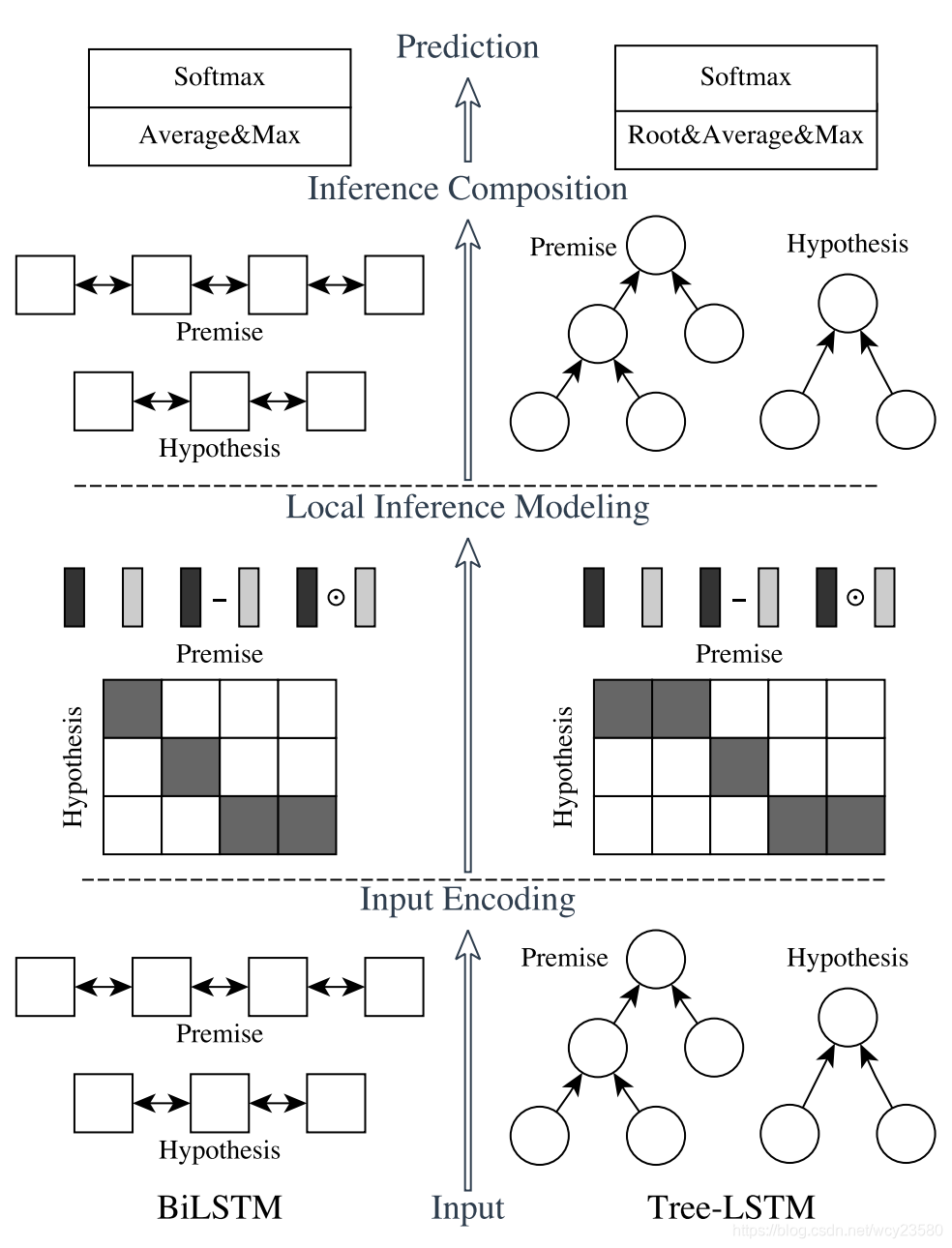
ESIM是左边的模型,主要分为三部分:Input Encoding、Local Inference Modeling、Inference Composition。
Input Encoding
这部分主要是对于输入的两句话(Premise和Hypothesis)分别进行embedding和BiLSTM来解码。
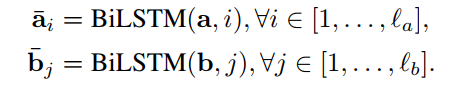
$l_a$和$l_b$分别表示Premise和Hypothesis句子的长度,另外$a_i$、$b_i$就是Premise和Hypothesis的某个单词的表示。
使用BiLSTM可以学习如何表示一句话中的word和它上下文的关系,我们也可以理解成这是在wordEmbedding之后,结合当前局的语境encoding得到新的embedding向量。
Local Inference Modeling
接下来我们需要分析这两个句子之间的联系,我们得到句子和单词的表示向量是基于当前语境以及单词之间的意思综合分析得到的。如果两个单词之间的联系大,就意味着他们之间的距离和夹角越小。所以这里使用点积的方式来计算$a^→$和$b^→$的attention权重。
然后计算两个句子的交互表示:
这里就是用注意力机制来计算新的词向量表示,第一个公式代表对权重矩阵按行softmax求权重,然后求与b的加权和来代表a的新序列。比如premise中有一个单词“I”,首先让“I”与hypothesis中的各词相乘并且标准化后作为权重,用另一句话中的各个词向量按照权重去表示“I”。这样如此得到新的序列,以上称为Local Inference Modelling。这里的注意力机制实现了局部推断。
Inference composition
接下来就是分析差异,从而判断两个句子之间的联系是否足够大了,ESIM主要是计算新旧序列之间的差和积,并把所有信息合并起来储存在一个序列中,以此来增强局部推理信息。
Inference Composition
使用BiLSTM来提取
然后将
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!